Benson Tucker — Code Projects
Open Source Data Work Portfolio
Project maintained by bhtucker Hosted on GitHub Pages — Theme by mattgraham
Note!
I'm currently writing in much more detail about current projects on my blog here.
Who Am I?I'm Benson Tucker, a scientist, engineer, analyst, and architect of various things data. I've worked in real estate tech, bridging my past life as an urban studies student to my current life as a technologist, as well as in e-commerce SaaS, bringing real-time brand interactions to online retail with ChatID.
I spend my brain cycles on conditional probability, scaleable data products, and reformulating business problems through graphical models. I graduated with Latin and Greek honors from Brown University in 2013 and achieved a certificate in Data Science from Columbia Engineering School in 2015.
On this Site
My github projects touch on many topics I work on professionally and provide a glimpse into my own thinking and style. I've prioritized showing a range of my own work over providing any enterprise-ready solutions to these real world problems.
Click each project header to see the repo!
Ad Sim
Suppose you have a rich marketing asset that is the ultimate in branded content. Someone a bit interested in the brand might react great, while someone totally uninterested might get spooked. The Ad Sim project models this situation.
On one side, users browse (and potentially purchase) according to their hidden preferences about brands. On the other, an ad server tracks these users and tries to decide when an ad would be more likely to help than to hurt. Complete with conversion events and product prices, this sets up a whole real-time optimization and learning problem.
Machine Learning Jams
The electronic half of the coursework for a Machine Learning course, this repo has Python implementations of supervised topics like multiclass classifiers, ensemble methods like adaptive boosting, and unsupervised topics like clustering and matrix factorization.
Entity Fusion in Messy Data about Networks
This demonstration of loose string matching takes artifically poor quality input data and derives cleaner relationships among humans and businesses. Drawn from the case of a database of real estate deals, I use string clustering and association analysis to answer the question: who do these brokers work for?
UN Development Program Hackathon: Understanding Global Resource Extraction
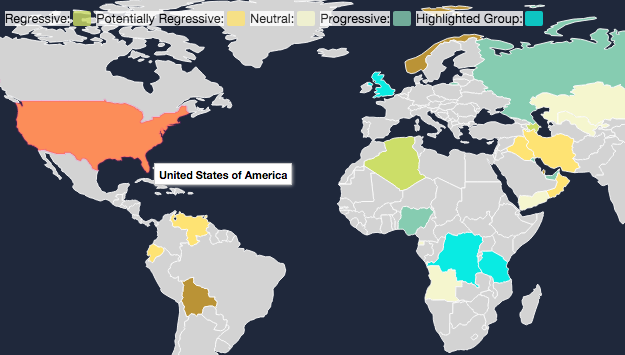
Using by-country data on resource extraction, price, volume, and tax revenues, my group was able to score many resource-rich countries around the world as to whether their taxation regimes were progressive (ie, captured a higher share of extraction revenues when extraction was more profitable) or regressive (the opposite case).